
Share Insight
Idea In Brief
AI evaluation means different things to different people
Model benchmarks, applications, systems and organisational context reflect distinct goals, methods and impacts that should not be confused or substituted.
Most evaluations prioritise benchmarks, not impact
Evidence shows the field overwhelmingly measures technical performance, while only a small fraction assesses how AI changes outcomes in settings.
Effective evaluation starts by defining focus
Clarity about what is being evaluated shapes metrics, methods and decisions, and determines whether AI delivers value within organisations sustainably.
As governments and businesses seek to understand the impact of AI there is growing recognition of the need to evaluate AI models and systems. Indeed, “AI evaluation” is fast becoming a new area of multidisciplinary research and a term used by technical practitioners, business professionals and policy specialists.
But what exactly is an AI evaluation? Opinions differ.
The most comprehensive look at the field comes from the Leverhulme Centre for the Future of Intelligence at Cambridge, which reviewed more than 125 recent studies and identified a distinct set of evaluation paradigms underpinned by a range of different objectives, methodologies and assumptions. A striking finding: 57 per cent focused on benchmarking model performance, while just 3 per cent measured real-world impact.
AI evaluation is determined by the actor
Confusion about the term “AI evaluation” with the different perspectives of those using it.
- Foundation model developers like Anthropic and OpenAI tend to focus on technical benchmarks: how does our latest model perform against competitors on standardised tests?
- Systems integrators like Microsoft and Salesforce care about adoption and security compliance within enterprise workflows.
- Policy researchers push for something broader: socio-technical evaluations that ask whether AI is producing fair outcomes.
- Organisational leaders tend to be most concerned with the outcomes and impacts of AI tools for their staff and organisation.
None of these perspectives are wrong. But they're not interchangeable, either. For example, while foundation model developers might test singular tasks that someone might do in the real world (see GDPval), they are not testing what happens when real people use this output in their organisations.
Understanding the components of AI systems
To provide conceptual clarity around the term “AI evaluation,” and to ensure it does not become a piece of unhelpful jargon, it is useful to distinguish between different components of AI systems.
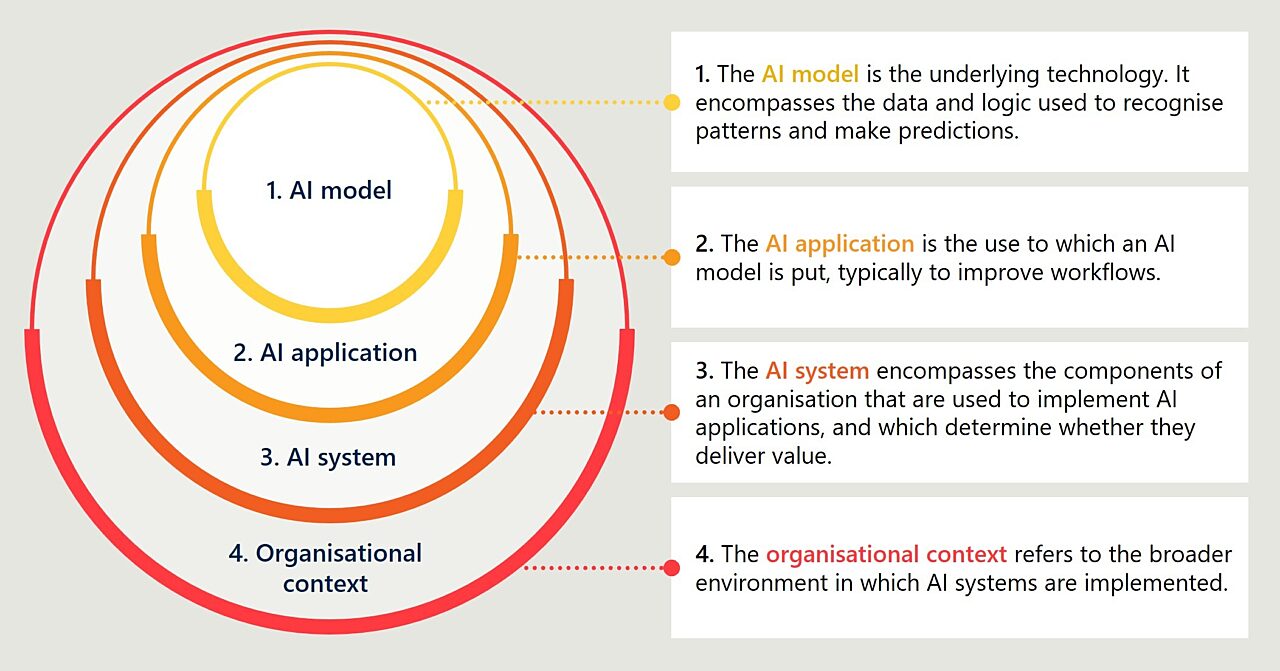
First is the AI model itself. This is the underlying technology that has been trained on data to recognise patterns and generate outputs such as predictions, classifications, or text. Think of models like Sonnet-4.6, GPT-5.2, or Gemini-3.1. Evaluating at this level involves asking questions like: How does this model perform on the tasks that matter to my organisation? How does it compare to other models?
Next is the AI application. This is where models are integrated into specific tools and workflows to deliver value, such as a customer service chatbot, a document analysis tool, or a coding assistant. This includes common AI applications like Copilot or ChatGPT. Evaluating at this level involves asking questions like: Does this application actually make our workflow more efficient? Does it integrate well with our existing systems? Is it reliable and fit for purpose?
Then we have the AI system. This encompasses the application as well as the components of an organisation in which it is implemented that determines how it is deployed and whether it can deliver value: infrastructure and data governance, the people using the tools, governance arrangements and risk management processes, feedback loops to refine performance, and audit trails to ensure oversight.
Evaluating at this level involves asking questions like: Do we have the right infrastructure and data foundations to support this AI application? Does our organisation have the right processes and capabilities to manage AI-related risks? What does use of the AI system look like in the real world?
Finally, we have the broader organisational context. This encompasses the AI system as well as all of the other parts of an organisation – its mission, strategy, culture, structure, assets, and so on – that may influence or be influenced by the use of AI tools. This level recognises that AI systems are not implemented in a vacuum: their effects will depend on the physical and digital environments in which they are used.
Evaluating at this level involves asking questions like: What are the organisation-wide effects of using AI? Are the AI tools aligned with our organisation’s mission and strategy? Are we seeing the business outcomes we expected? Are there any unintended consequences?
To help answer these questions it can help to situate AI in your organisational architecture. We have previously written at length about how vision and mission should guide AI adoption.
Be clear about what you are evaluating
These different components – models, applications, systems and organisational context – are interdependent. Model performance matters, but it doesn't guarantee application success. And even a well-performing application won't deliver value if the broader organisational context doesn’t support it.
A good AI evaluation begins by identifying which circle you're most interested in: that is, what is the primary object of your evaluation? That will have a significant bearing on your evaluation focus and your approach to data collection and analysis.
But that's only step one. Once you know your focus area, you still need to think hard about what you want to measure. As this article has shown, this is not simply a technical question, and it doesn't simply involve measuring uptake of AI tools. We will explore this further in our next article.
Get in touch to discuss how your organisation can embrace the potential of AI.
Connect with Joshua Sidgwick, Charlotte Bradley, and Will Prothero on LinkedIn.
This is the first article in our series on AI evaluation. Read the second article here and the third article here.
Authors

Joshua Sidgwick
Director
With a passion for data and strategy, Joshua excels in partnering on high stakes problems. From delivering pandemic statistics to pioneering national data infrastructure, he is experienced in translating data into strategic advantage.

Charlotte Bradley
Director
Charlotte blends analytical rigour with creativity and compassion to deliver strategic outcomes across sectors.
